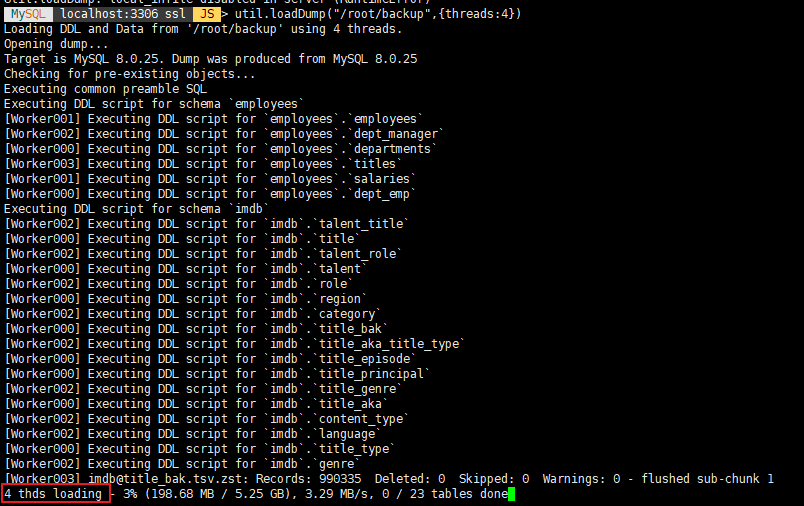
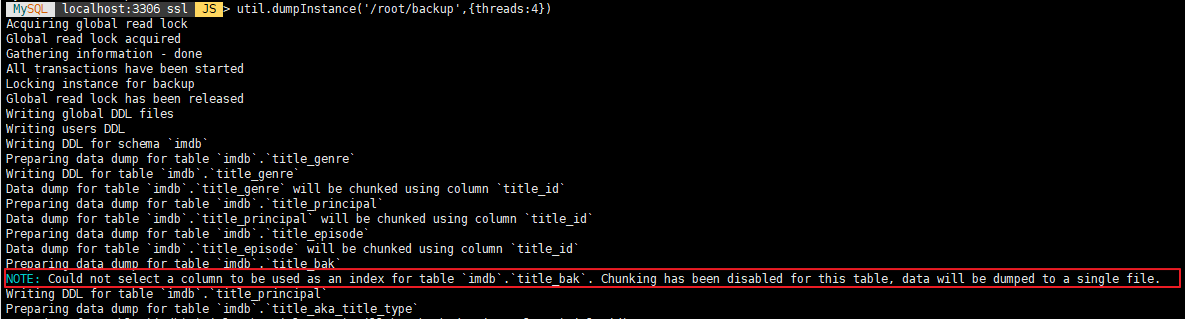
util.dumpInstance('/root/backup',{threads:4}) 로 백업을 하면 아래와 같은 메시지가 나온다.
사요할 수 있는 인덱스가 없어서 Chunking 을 못한다.
thread 4개로 덤프한다는 메시지 이외에는 특별한 메시지는 없다.
제러럴 로그를 보면 dump 하면서 아래의 항목들을 확인한다.
- DB
- 테이블
- 테이블 정보 (컬럼명, 데이터 타입)
- 테이블 PK
- 컬럼 통계
- DB 계정
- 사용하지 않는 DB계정 (패스워드 미설정, 만료상태, 잠금상태)
- 이벤트
- 프로시저, 함수
- 트리거
- 백업 실행 계정의 보유 권한
- 플러그인 상태
- NDBCLUSTER 사용 여부
- 백업 실행 계정의 스키마, 테이블 권한
- 백업 실행 계정의 기본 role
이제 백업을 시작한다.
- SHOW CREATE USER 계정 - SHOW GRANTS FOR 계정 - SHOW CREATE DATABASE IF NOT EXISTS 디비
여기서 부터는 지정한 thread 수의 thread 가 진행한다.
- show create table 테이블
- show fields from 테이블
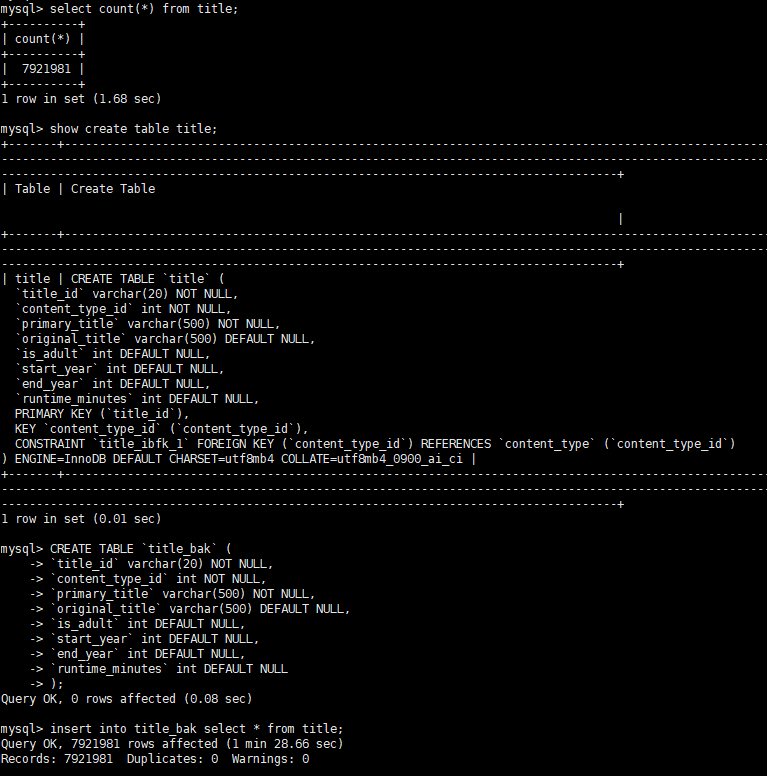
※ pk가 있고 없는 title, title_bak 테이블을 비교한다.
title 테이블
- 테이블 PK 의 MIN/MAX 값 확인
- SELECT SQL_NO_CACHE MIN(`title_id`), MAX(`title_id`) FROM `imdb`.`title` - SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 0 */
- SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 0 */
chunk ID: 1 ~ 11까지 아래와 같은 쿼리가 실행된다.
pk 값으로 chunk 를 나눌 범위를 구하는듯.
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt0718077' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 1 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt0718077' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 1 */
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt10740924' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 2 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt10740924' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 2 */
....
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt9348300' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 11 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt9348300' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 11 */
위에서 확인한 pk 값으로 chunk 를 나누어서 덤프
SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt0000001' AND 'tt0718077' OR `title_id` IS NULL ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 0 */ SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt0718078' AND 'tt10740924' ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 1 */
....
SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt9348302' AND 'tt9916880' ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 11 */
MySQL은 클라이언트가 MySQL 서버에 접속할 때마다 해당 클라언트에 Thread를 생성하고 해당 커넥션이 종료되면 Thread를 제거한다.
생성되어 있는 Thread수가 커넥션수라고 보면된다.
Threads_cached 는 thread_cache_size 로 설정되며 설정된 값만큼 Thread 재사용을 위해서 Thread 를 가지고 있는다.
다음에 쓸께 하고 짱박는 느낌?
여기서 맞을수 있는 장애는.. 갑자기 급격하게 커넥션이 늘어나면서 Threads Cache에서 가지고 있는 Thread를 다 사용하면 Thread 를 만들게 된다. (Thread_create 발생) 이때 병목현상이 발생하여 커넥션이 늦어지거나 쿼리 응답속도가 늦어지는 현상이 발생할 수도 있다.
접속이 끊긴 세션도 발견되었다. 이건 SR 진행해봐야겠다.
mysql 메뉴얼에서는 8 + (max_connections / 100) 으로 잡으라고 되어 있다.
CREATE DATABASE zipcode;
use zipcode;
CREATE TABLE zipcode (
zipcode VARCHAR(5) NULL,
sido VARCHAR(25) NULL,
sido_en VARCHAR(20) NULL,
sigungu VARCHAR(30) NULL,
sigungu_en VARCHAR(30) NULL,
eupmyun VARCHAR(20) NULL,
eupmyun_en VARCHAR(25) NULL,
doro_code VARCHAR(12) NULL,
doro VARCHAR(40) NULL,
doro_en VARCHAR(50) NULL,
under_yn VARCHAR(1) NULL,
buildno1 VARCHAR(5) NULL,
buildno2 VARCHAR(4) NULL,
buildnum VARCHAR(25) NULL,
multiple VARCHAR(1) NULL,
buildname VARCHAR(70) NULL,
dong_code VARCHAR(10) NULL,
dong VARCHAR(20) NULL,
ri VARCHAR(20) NULL,
dong_hj VARCHAR(30) NULL,
mount_yn VARCHAR(1) NULL,
jibun1 VARCHAR(4) NULL,
eupmyundong_no VARCHAR(2) NULL,
jibun2 VARCHAR(4) NULL,
zipcode_old VARCHAR(7) NULL,
zipcode_seq VARCHAR(3) NULL,
seq BIGINT NOT NULL AUTO_INCREMENT,
PRIMARY KEY(seq)
) NGINE=InnoDB DEFAULT CHARSET=utf8mb4;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/강원도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/경기도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/경상남도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/경상북도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/광주광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/대구광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/대전광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/부산광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/서울특별시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/세종특별자치시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/울산광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/인천광역시.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/전라남도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/전라북도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/제주특별자치도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/충청남도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
LOAD DATA LOCAL INFILE '/root/zipcode_DB/충청북도.txt' INTO TABLE zipcode.zipcode CHARACTER SET 'utf8mb4' FIELDS TERMINATED BY '|' IGNORE 1 LINES;
sigungu 를 algorithm=inplace 로 varchar(30) -> varchar(63) 로 바꾸어보자!