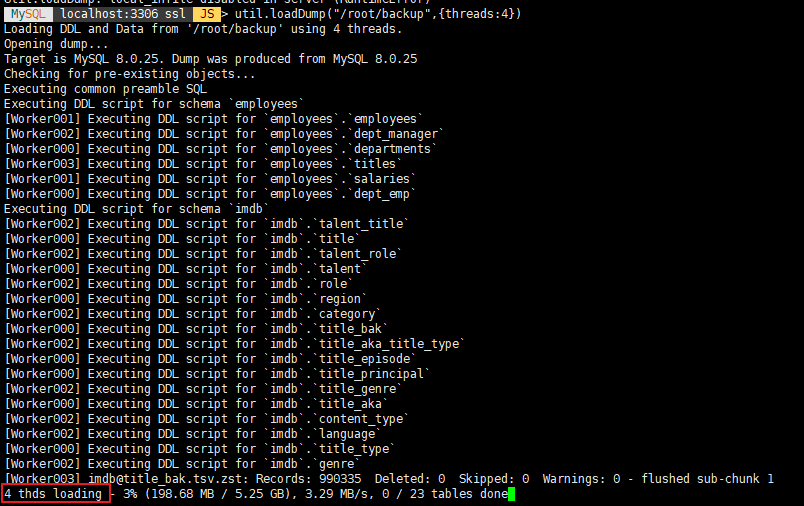
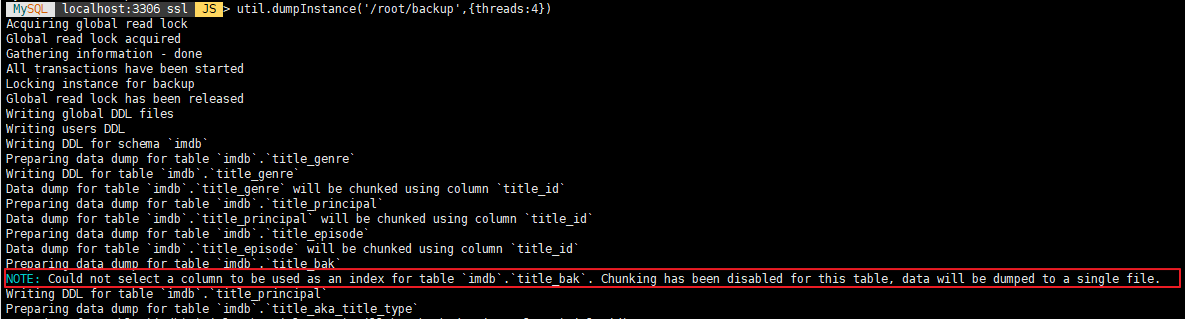
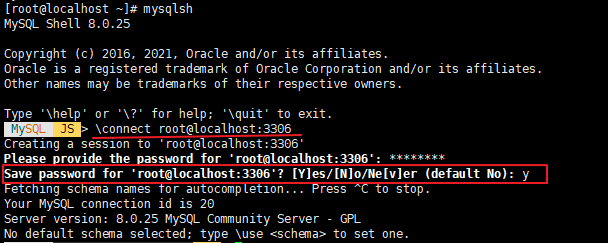
util.dumpInstance('/root/backup',{threads:4}) 로 백업을 하면 아래와 같은 메시지가 나온다.
사요할 수 있는 인덱스가 없어서 Chunking 을 못한다.
thread 4개로 덤프한다는 메시지 이외에는 특별한 메시지는 없다.
제러럴 로그를 보면 dump 하면서 아래의 항목들을 확인한다.
- DB
- 테이블
- 테이블 정보 (컬럼명, 데이터 타입)
- 테이블 PK
- 컬럼 통계
- DB 계정
- 사용하지 않는 DB계정 (패스워드 미설정, 만료상태, 잠금상태)
- 이벤트
- 프로시저, 함수
- 트리거
- 백업 실행 계정의 보유 권한
- 플러그인 상태
- NDBCLUSTER 사용 여부
- 백업 실행 계정의 스키마, 테이블 권한
- 백업 실행 계정의 기본 role
이제 백업을 시작한다.
- SHOW CREATE USER 계정 - SHOW GRANTS FOR 계정 - SHOW CREATE DATABASE IF NOT EXISTS 디비
여기서 부터는 지정한 thread 수의 thread 가 진행한다.
- show create table 테이블
- show fields from 테이블
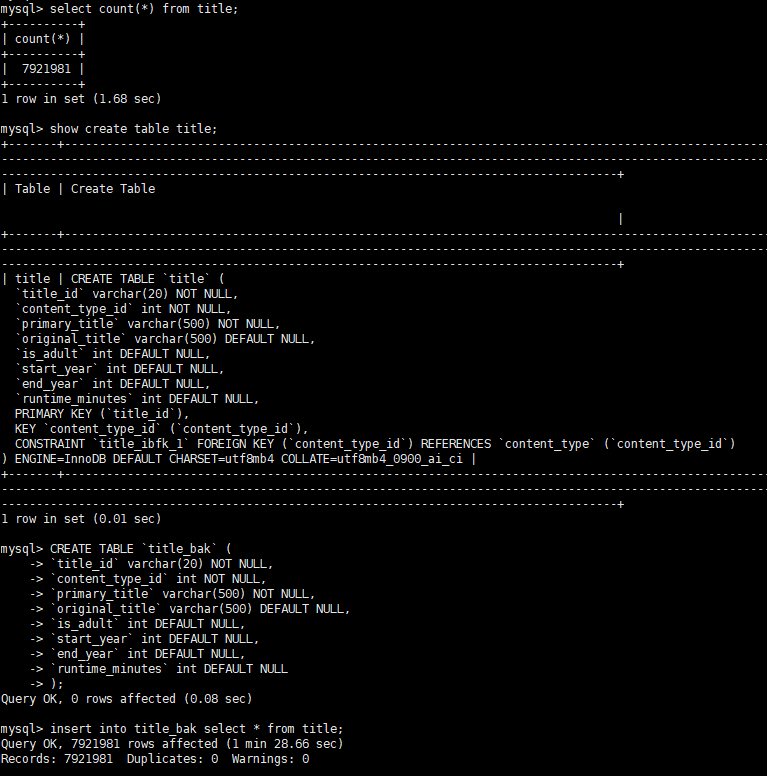
※ pk가 있고 없는 title, title_bak 테이블을 비교한다.
title 테이블
- 테이블 PK 의 MIN/MAX 값 확인
- SELECT SQL_NO_CACHE MIN(`title_id`), MAX(`title_id`) FROM `imdb`.`title` - SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 0 */
- SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 0 */
chunk ID: 1 ~ 11까지 아래와 같은 쿼리가 실행된다.
pk 값으로 chunk 를 나눌 범위를 구하는듯.
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt0718077' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 1 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt0718077' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 1 */
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt10740924' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 2 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt10740924' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 2 */
....
SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt9348300' ORDER BY `title_id` LIMIT 0,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 11 */ SELECT SQL_NO_CACHE `title_id` FROM `imdb`.`title` WHERE `title_id` > 'tt9348300' ORDER BY `title_id` LIMIT 695651,1 /* mysqlsh dumpInstance, chunking table `imdb`.`title`, chunk ID: 11 */
위에서 확인한 pk 값으로 chunk 를 나누어서 덤프
SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt0000001' AND 'tt0718077' OR `title_id` IS NULL ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 0 */ SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt0718078' AND 'tt10740924' ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 1 */
....
SELECT SQL_NO_CACHE `title_id`,`content_type_id`,`primary_title`,`original_title`,`is_adult`,`start_year`,`end_year`,`runtime_minutes` FROM `imdb`.`title` WHERE `title_id` BETWEEN 'tt9348302' AND 'tt9916880' ORDER BY `title_id` /* mysqlsh dumpInstance, dumping table `imdb`.`title`, chunk ID: 11 */
MySQL 8.0 이 출시된지 3년이 지났다. 현재 시점에서는 8.0을 사용하는것을 권장한다.
8.0 에서 성능 향상 - Read / Write 에 대한 부분도 있지만, IO Capactiy 활용률 개선과 경합이 많은 작업들 컨텐션이 많은 작업들을 이전에는 FIFO 방식으로 처리 했지만 CATS(Contention Aware Transaction Scheduling) 라는 알고리즘을 도입해서 빈번하게 자주 들어오는것에 대해서 웨이트를 높게줘서 빨리 처리되게 하는 부분을 도입했다. - 리소스 그룹, Read, Write 별 Thread 수 할당 가능 - UTF8MB4 가 기본 케릭터셋이 되면서 관련된 성능 개선 - 5.7 에서는 JSON/BLOB 에서는 업데이트시 전체를 업데이트되어 IO가 많이 발생하였으나
이제 업데이트된 부분만 변경한다. - 데이터 딕셔너리가 도입되었다. 모든 시스템에 있던 파일들이 다 innodb table로 들어갔다. information schema, performance schema 에 있던것들도 인덱스나 쿼리리를 사용해서 조회 가능
하드웨어/OS 튜닝
Memory innodb buffer pool size 을 크게 가져갈수록 디스크 IO를 줄일수 있다. mysql이 가용가능한 메모리의 70~80%를 할당하고 가이드한다. - 10G기가 이하의 서버에서는 60~70% 권장 - 처음에는 70~80% 할당후 사이트에 맞게 튜닝 권장 메모리 튜닝을 할때 OS, FS Cache, Temporary 테이블을 사용하는 부분이 감안이 되어야 한다.
CPU 하이퍼 스레딩 활성화 더 빠른 멀티 코어 프로세서 사용 권장 CPU , IO, Memory 에 우선을 두자면 각 사이트의 주요 잡이 어떤것인지 봐야한다. 보통 CPU 보다는 Memory나 IO에 더 신경을 쓰는것이 성능 향상에 도움이 된다. MySQL 버전에 따른 코어수 제한이 있다. - MySQL 5.1 : ~ 4코어 - MySQL 5.5 : ~ 16코어 - MySQL 5.6 : ~ 36 쓰레드(Core) - MySQL 5.7 : ~ 64 쓰레드(32 Core-HT) - MySQL 8.0 : ~ 100 쓰레드(48 Core-HT)
Disk SSD, NVMe 사용시 innodb_page_size=4K, innodb_flush_neighbors=0 로 사용을 추천함 - 신규로 세팅되는 서비스의 경우 추천 사용중인 DB를 SSD로 변경후 적용시 성능향상 없음 - innodb datadir, tmp 파일 및 undo 로그 모두 Ramdom IO가 발생함으로 SSD로 할당하고 로그(빈로그 등등)의 경우 Sequnential IO가 발생함으로 디스크로 할당하는것을 추천
OS MySQL은 Linux 에 최적화 되어 있다. - 성능을 위해서는 Linux 를 추천한다. ulimit 로 파일/프로세스수 제한 - MySQL 이외에 OS에서 설정을 해줘야되는 부분 - ulimit -n, 파일 수 제한 (connections, open tables, ...) - ulimit -u, 스레드 수 제한 (connections, InnoDB background threads, event scheduler, ....) NUMA 기반 서버의 경우 innodb_numa_interleave를 1로 설정 InnoDB를 사용하는 경우 파일시스템 캐시를 사용안해도 된다. - buffer pool 이 데이터 캐시 형태로 사용함 - set inndbo_flush_method=O_DIRECT - 파일 시스템 캐시는 MySQL의 다른 부분(로그)에서 사용함으로 비활성화하지 않는다.
MySQL 설정값 확인 방법
8.0부터 my.cnf 외에 mysqld-auto.cnf 가 추가 되었다.
- 커맨드 라인에서 SET PERSIST 변수=값 지정시 mysqld 재기동시 설정된 값이 초기화 되었다.
SET PERSIST로 설정값이 mysqld-auto.cnf 파일에 저장되어 mysqld 재기동 이후에도 유지된다.
- show [session|global] variables 로 조회 - show [session|global] variables like '%보고 싶은것%'; - performance_schmea 에서 조회 가능 - performance_schmea.global_variables - performance_schmea.session_variables - performance_schmea.variables_by_thread - performance_schmea.threads 의 thread_id 에 connection 을 매핑 - 설정값을 누가 언제 변경했는지 확인 가능 - performance_schmea 에서 확인 가능
InnoDB buffer pool 과 redo log - innodb_buffer_pool_size - 메모리에 DB페이지를 저장하기 위한 메모리 사이즈 - MySQL에서 사용가능한 메모리의 70~80% 할당 권장 - 각 서비스의 특성이 맞게 튜닝 필요 - MySQL 5.7 부터 innodb_buffer_pool_size 를 동적으로 변경 가능 - innodb_log_file_size (redo log 사이즈) - 이부분을 크게 가져가면 쓰기 속도가 빨라진다. - 서버가 재기동하면서 복구할때 사용하는 영역으로 사이즈를 너무 크게 잡을 경우 DB 복구시간이 느려진다. - 운영서버 최소 512MB 권장 - innodb_log_files_in_group 에 의해 결정된 총 redo log 용량 (기본값은 2) - 대부분 3을 사용하는편
Trading performance over consistency (AICD 에 D에 해당하는 부분) - Commit 된 트랜잭션에 대해 InnoDB flush/sync 는 언제해야 할까? - innodb_flush_log_at_trx_commit - 0 : commit 되면 redo log를 메모리에 기록하고 매 1초마다 메모리에서 디스크로 flush - 1 (기본값) : 완전한 ACID 지원, 매 commit 마다 redo log 에 기록하고 디스크에 flush - 2 : commit 되면 O/S Buffer로 Redo Log가 기록되고 매 1초마다 메모리(O/S Buffer)에서 디스크로 flush 함 - 다음 경우를 제외하고 1을 권장(일관성을 위해) - 대량 데이터를 로딩할 때 로드 하는 동안 세션 변수를 2로 설정하고 데이터를 로드하는 경우 mysql 8.0.21 버전을 사용하는 경우 redo-logging 을 비활성화 할 수도 있다. - 예상치 못한 엄청난 부하(디스크)를 경험하고 있는데 문제를 해결할 동안 일단 서버가 어떻게든 동작해야 하는 경우
Buffers that are per client connections - connection(세션)당 할당되는 버퍼들 - read_buffer_size : Sequnential scan (full table scan)을 사용할 때 사용하는 버퍼 - read_rnd_buffer_size : 정렬 작업후, 정렬된 순서대로 데이터를 다시 읽어 들일 때 사용하는 버퍼 - join_buffer_size : 인덱스를 사용하지 않는 조인에 사용되는 버퍼 Session level에서 join 단위로 생성 - sort_buffer_size : 인덱스를 사용하지 않는 정렬에 사용하는 버퍼 - binlog_cache_size (if binary logginigs is enabled) - connection이 많을 경우 이 버퍼들이 메모리를 점유하기 때문에 크게 세팅하면 안된다. 만약 크게 필요한 경우가 있다면 필요한 세션에서만 크게 잡아서 사용한다.
Analyzing queries - EXPLAIN - optimizer 의 실행 계획을 보여줌 실데이터가 아닌 카디널러티를 가지고 만든 실행계획 - EXPLAIN ANALYZE - 8.0.19에 추가됨 실제 데이터를 가지고 만든 실행계획 - SET profiing=1, 프로파일링 활성화 (SHOW PROFILES, SHOW PROFILE FOR QUERY X) - MySQL 8.0 기준 - Optimizer trace (가능한 모든 optimizer 실행 계획 확인)