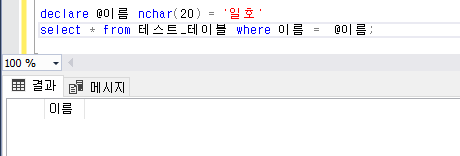
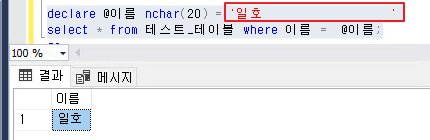
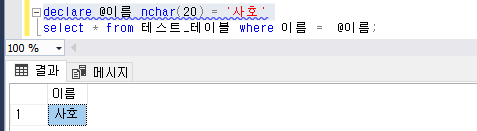
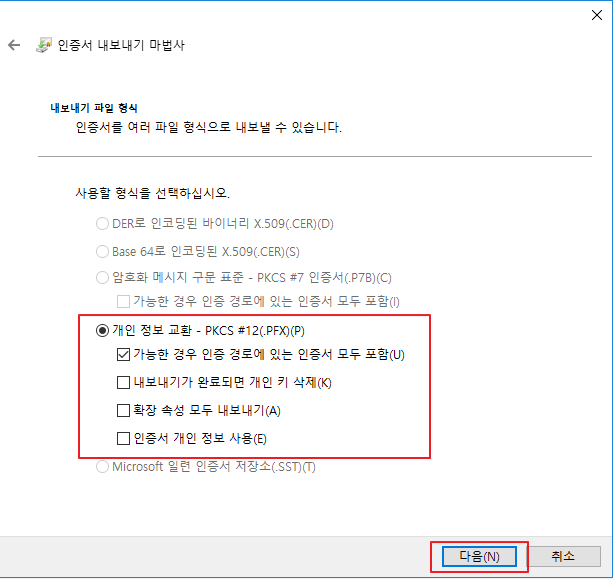
MySQL 5.7.8 부터 JSON 을 지원한다.
JSON 문서 내의 값에서 Generated Column을 생성한 다음 해당 컬럼을 인덱싱하면 실제로 JSON 필드를 인덱싱할 수 있다.
JSON 테스트 데이터
{
"id": 1,
"name": "Sally",
"games_played":{
"Battlefield": {
"weapon": "sniper rifle",
"rank": "Sergeant V",
"level": 20
},
"Crazy Tennis": {
"won": 4,
"lost": 1
},
"Puzzler": {
"time": 7
}
}
}
테스트 테이블 생성
CREATE TABLE `players` (
`id` INT UNSIGNED NOT NULL,
`player_and_games` JSON NOT NULL,
`names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`player_and_games` ->> '$.name') NOT NULL,
PRIMARY KEY (`id`)
);
위 DDL문에서 아래 부분이 JSON 타입 컬럼 player_and_game 에서 name 속성 값을 참조하는 Generated Column (names_virtual) 을 지정한 부분이다.
`names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`player_and_games` ->> '$.name')
Generated Column 에 지정할수 있는 제약조건은 아래와 같다.
[VIRTUAL|STORED] [UNIQUE [KEY]] [[NOT] NULL] [[PRIMARY] KEY]
VIRTUAL, STORED는 컬럼의 값이 실제로 저장되는지 여부를 나타낸다.
- VIRTUAL : 기본값, 컬럼의 값 저장안함, 저장 공간없음, 행을 읽을 때마다 계산해서 처리한다.
인덱스를 생성하면 값이 인덱스 자체에 저장된다.
- STORED : 데이터가 테이블에 저장(입력,수정)될때 컬럼의 값도 저장된다.
인덱스는 일반적인 인덱스와 동일하게 처리된다.
아래에 테스트 소스 깃헙에 있는 mysql-json.sql 파일에 있는 insert 문을 사용한다.
INSERT INTO `players` (`id`, `player_and_games`) VALUES (1, '{
"id": 1,
"name": "Sally",
"games_played":{
"Battlefield": {
"weapon": "sniper rifle",
"rank": "Sergeant V",
"level": 20
},
"Crazy Tennis": {
"won": 4,
"lost": 1
},
"Puzzler": {
"time": 7
}
}
}'
);
....
입력된 데이터 확인, names_virtual 컬럼에서 JSON 문서의 name 속성값 확인됨
mysql> select * from players;
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+
| id | player_and_games | names_virtual |
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+
| 1 | {"id": 1, "name": "Sally", "games_played": {"Puzzler": {"time": 7}, "Battlefield": {"rank": "Sergeant V", "level": 20, "weapon": "sniper rifle"}, "Crazy Tennis": {"won": 4, "lost": 1}}} | Sally |
| 2 | {"id": 2, "name": "Thom", "games_played": {"Puzzler": {"time": 25}, "Battlefield": {"rank": "Major General VIII", "level": 127, "weapon": "carbine"}, "Crazy Tennis": {"won": 10, "lost": 30}}} | Thom |
| 3 | {"id": 3, "name": "Ali", "games_played": {"Puzzler": {"time": 12}, "Battlefield": {"rank": "First Sergeant II", "level": 37, "weapon": "machine gun"}, "Crazy Tennis": {"won": 30, "lost": 21}}} | Ali |
| 4 | {"id": 4, "name": "Alfred", "games_played": {"Puzzler": {"time": 10}, "Battlefield": {"rank": "Chief Warrant Officer Five III", "level": 73, "weapon": "pistol"}, "Crazy Tennis": {"won": 47, "lost": 2}}} | Alfred |
| 5 | {"id": 5, "name": "Phil", "games_played": {"Puzzler": {"time": 7}, "Battlefield": {"rank": "Lt. Colonel III", "level": 98, "weapon": "assault rifle"}, "Crazy Tennis": {"won": 130, "lost": 75}}} | Phil |
| 6 | {"id": 6, "name": "Henry", "games_played": {"Puzzler": {"time": 17}, "Battlefield": {"rank": "Captain II", "level": 87, "weapon": "assault rifle"}, "Crazy Tennis": {"won": 68, "lost": 149}}} | Henry |
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+
6 rows in set (0.00 sec)
players 테이블 컬럼 정보 확인
mysql> show columns from players;
+------------------+--------------+------+-----+---------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+------------------+--------------+------+-----+---------+-------------------+
| id | int unsigned | NO | PRI | NULL | |
| player_and_games | json | NO | | NULL | |
| names_virtual | varchar(20) | NO | | NULL | VIRTUAL GENERATED |
+------------------+--------------+------+-----+---------+-------------------+
Extra 에 VIRTUAL GENERATED 으로 Generated Column 이 VIRTUAL 인것을 보여준다.
STORED 로 지정된 컬럼의 경우 STORED GENERATED 로 표시된다.
Battlefield 레벨, 승리한 테니스 게임, 패배한 테니스 게임 및 퍼즐 게임 시간 컬럼을 추가한다.
ALTER TABLE `players` ADD COLUMN `battlefield_level_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played.Battlefield.level') NOT NULL AFTER `names_virtual`;
ALTER TABLE `players` ADD COLUMN `tennis_won_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played."Crazy Tennis".won') NOT NULL AFTER `battlefield_level_virtual`;
ALTER TABLE `players` ADD COLUMN `tennis_lost_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played."Crazy Tennis".lost') NOT NULL AFTER `tennis_won_virtual`;
ALTER TABLE `players` ADD COLUMN `times_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played.Puzzler.time') NOT NULL AFTER `tennis_lost_virtual`;
mysql> show columns from players;
+---------------------------+--------------+------+-----+---------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+---------------------------+--------------+------+-----+---------+-------------------+
| id | int unsigned | NO | PRI | NULL | |
| player_and_games | json | NO | | NULL | |
| names_virtual | varchar(20) | NO | | NULL | VIRTUAL GENERATED |
| battlefield_level_virtual | int | NO | | NULL | VIRTUAL GENERATED |
| tennis_won_virtual | int | NO | | NULL | VIRTUAL GENERATED |
| tennis_lost_virtual | int | NO | | NULL | VIRTUAL GENERATED |
| times_virtual | int | NO | | NULL | VIRTUAL GENERATED |
+---------------------------+--------------+------+-----+---------+-------------------+
Generated Column을 검색하는 쿼리 실행계획 확인
mysql> EXPLAIN SELECT * FROM `players` WHERE `names_virtual` = "Sally"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: players
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
해당 컬럼에 인덱스 생성하고 실행계획 확인, 생성한 인덱스 인덱스 잘탄다.
mysql> CREATE INDEX `names_idx` ON `players`(`names_virtual`);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT * FROM `players` WHERE `names_virtual` = "Sally"\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: players
partitions: NULL
type: ref
possible_keys: names_idx
key: names_idx
key_len: 82
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
다른 Generated Column 들도 인덱스를 생성하고, 생성된 인덱스를 확인한다.
mysql> CREATE INDEX `times_idx` ON `players`(`times_virtual`);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> CREATE INDEX `won_idx` ON `players`(`tennis_won_virtual`);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> CREATE INDEX `lost_idx` ON `players`(`tennis_lost_virtual`);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> CREATE INDEX `level_idx` ON `players`(`battlefield_level_virtual`);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM `players`;
+---------+------------+-----------+--------------+---------------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+-----------+--------------+---------------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| players | 0 | PRIMARY | 1 | id | A | 6 | NULL | NULL | | BTREE | | | YES | NULL |
| players | 1 | names_idx | 1 | names_virtual | A | 6 | NULL | NULL | | BTREE | | | YES | NULL |
| players | 1 | times_idx | 1 | times_virtual | A | 5 | NULL | NULL | | BTREE | | | YES | NULL |
| players | 1 | won_idx | 1 | tennis_won_virtual | A | 6 | NULL | NULL | | BTREE | | | YES | NULL |
| players | 1 | lost_idx | 1 | tennis_lost_virtual | A | 6 | NULL | NULL | | BTREE | | | YES | NULL |
| players | 1 | level_idx | 1 | battlefield_level_virtual | A | 6 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+-----------+--------------+---------------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
6 rows in set (0.03 sec)
STORED 로 지정된 Generated Column 을 사용하는 경우
1. PRIMARY KEY 를 잡아야될경우
2. 일반 BTREE 대신 FULLTEXT 또는 RTREE 인덱스가 필요한 경우
3. 인덱스를 사용하지 않는 스캔이 많이 발생하는 컬럼일 경우
테스트용 테이블 생성
CREATE TABLE `players_two` (
`id` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.id') STORED NOT NULL,
`player_and_games` JSON NOT NULL,
`names_virtual` VARCHAR(20) GENERATED ALWAYS AS (`player_and_games` ->> '$.name') NOT NULL,
`times_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played.Puzzler.time') NOT NULL,
`tennis_won_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played."Crazy Tennis".won') NOT NULL,
`tennis_lost_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played."Crazy Tennis".lost') NOT NULL,
`battlefield_level_virtual` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.games_played.Battlefield.level') NOT NULL,
PRIMARY KEY (`id`),
INDEX `times_index` (`times_virtual`),
INDEX `names_index` (`names_virtual`),
INDEX `won_index` (`tennis_won_virtual`),
INDEX `lost_index` (`tennis_lost_virtual`),
INDEX `level_index` (`battlefield_level_virtual`)
);
PK 컬럼을 STORED 로 지정하였다.
`id` INT GENERATED ALWAYS AS (`player_and_games` ->> '$.id') STORED NOT NULL,
SHOW COLUMNS 로 컬럼 확인
mysql> SHOW COLUMNS FROM `players_two`;
+---------------------------+-------------+------+-----+---------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+---------------------------+-------------+------+-----+---------+-------------------+
| id | int | NO | PRI | NULL | STORED GENERATED |
| player_and_games | json | NO | | NULL | |
| names_virtual | varchar(20) | NO | MUL | NULL | VIRTUAL GENERATED |
| times_virtual | int | NO | MUL | NULL | VIRTUAL GENERATED |
| tennis_won_virtual | int | NO | MUL | NULL | VIRTUAL GENERATED |
| tennis_lost_virtual | int | NO | MUL | NULL | VIRTUAL GENERATED |
| battlefield_level_virtual | int | NO | MUL | NULL | VIRTUAL GENERATED |
+---------------------------+-------------+------+-----+---------+-------------------+
출처 :
https://www.compose.com/articles/mysql-for-json-generated-columns-and-indexing/
https://dev.mysql.com/blog-archive/indexing-json-documents-via-virtual-columns/
테스트 소스 :
https://github.com/compose-ex/mysql-json-indexing-generated-columns/blob/master/mysql-json.sql