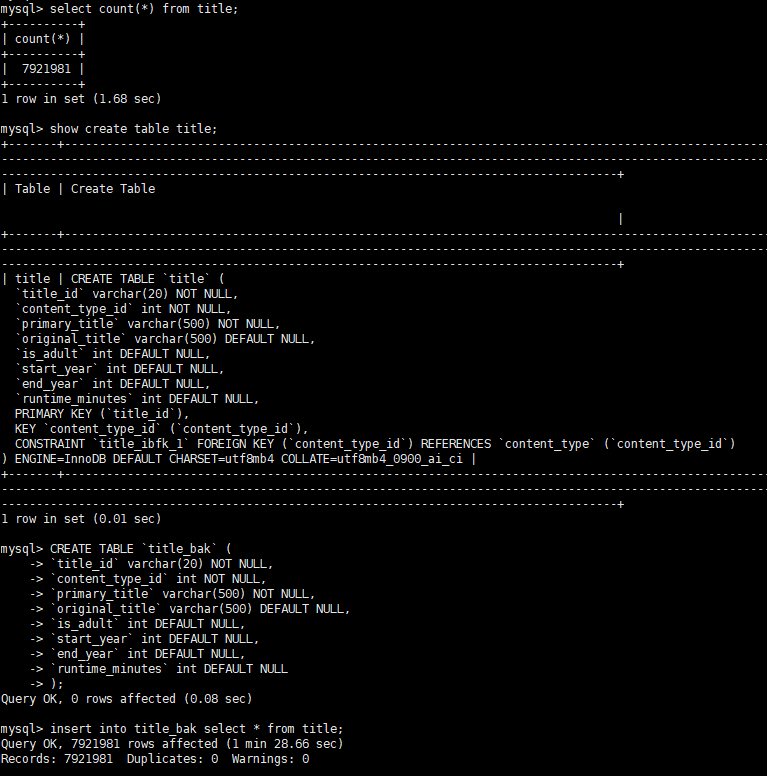
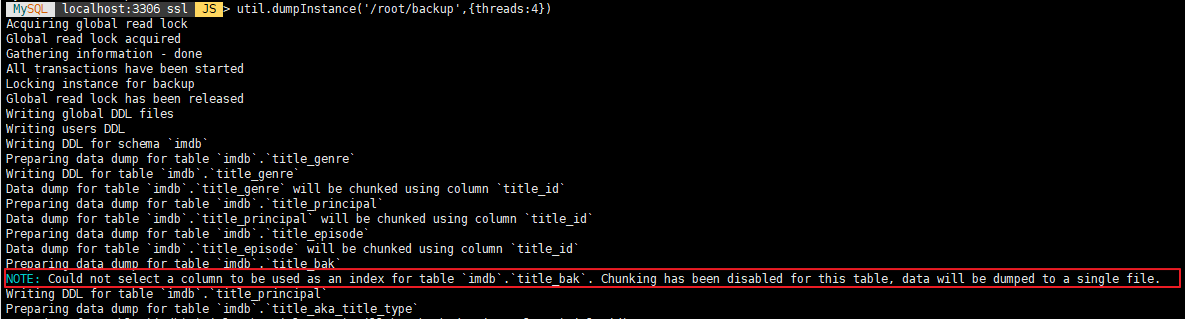
백업을 했으니 복원을 해야지..
너무나 당연한 것
util.loadDump 로 복원한다.
주의사항
- 복원할 MySQL 인스턴스는 5.7 이상이 필요하다.
- 복원시 LOAD DATA LOCAL INFILE 명령문을 사용함으로 local_infile 시스템 변수가 ON으로 설정되어 있어야한다.
- sql_require_primary_key 시스템 변수가 ON 으로 설정되어 있는 경우 덤프 파일에 PK가 없는 테이블이 있을 경우 오류를 반환한다.
특이사항 및 특징
- waitDumpTimeout 옵션 사용시 덤프중인 덤프를 복원할 수 있다.
- 테이블이 사용가능 해지면 로드되고 새 데이터가 덤프될때까지 지정된 시간(초) 동안 대기한다.
제한 시간이 경과하면 덤프가 완료된것으로 판단하고 가져오기를 중단한다.
- 복구 상태를 진행 상태 파일에 저장한다.
- 진행 상태 파일 저장 위치는 기본적으로 덤프 디렉토리에 생성된다.
load-process.server_uuid.json 파일 형태로 저장되며 저장위치, 파일명을 설정할 수 있다.
- 복원을 재개하거나 재시도 할때 진행 상태 파일을 참조하고 완료된 단계를 건너뛴다.
부분적으로 로드된 테이블에 대해 중복 제거가 자동으로 관리된다.
- Ctrl + C 로 중단후 대시 복원할때 중지된 단계에서 다시 진행된다.
- resetProgress 옵션으로 처음부터 다시 복원가능
이전에 로드된 모든 객체(디비, 테이블, 사용자, 뷰, 트리거 등등)을 수동으로 제거해야함.
- DDL 파일은 단일 스레드로 로드, 데이터는 지정한 스레드 수로 병렬 로드됨 (기본값 : 4)
덤프가 생성될때 테이블 데이터가 청크된 경우 여러 스레드를 사용가능
그렇지 않은 경우 각 스레드가 한번에 하나의 테이블을 로드함
- 병렬 처리 최대화를 위해 스레드간에 데이터 가져오기를 예약함
- 덤프시 mysql shell 에서 압축된 경우 별도의 압축 해제 옵션 필요 없음 (자동 해제)
주요 옵션
- dryRun : 지정된 옵션에 따라 복원시 노출되는 오류 및 단계를 보여준다.
단 실제 복원은 하지 않는다. (기본값 false)
- threads : 복원시 사용할 스레드 수 (기본값 4)
- progressFile : 덤프 로드 유틸리티의 진행 생태 저장 파일의 위치
- showProgress : 복원 진행 정보를 표시할지 여부 (기본값 true)
- resetProgress : true 로 지정시 복원을 처음부터 다시 한다.
복원시 미리 생성되어 있는 중복 오브젝트(디비, 테이블 등등)에 대한 제거를 하지 않는다.
수동으로 지워줘야 한다.
- waitDumpTimeout : 덤프 위치에 업로드된 모든 데이터 청크를 처리후 유틸리티가 추가 데이터를 기다리는
제한 시간(초)을 지정하여 동시 로드 활성화 (기본값 0)
- ignoreExistingObjects : true 로 지정시 복원중 중복객체 발견시 계속 진행 (기본값 false)
false 로 지정시 중복 객체 발견시 오류가 발생하고 복원을 중지한다.
- ignoreVersion : 덤프된 MySQL 과, 복원할 MySQL 의 주 버전 번호가 다를 경우 덤프를 가져올지 여부 (기본값 false)
- showMetadata : 덤프에 포함된 덤프 메타 데이터를 출력할지 여부
- updateGtidSet [off, append, replace] : 덤프 메타 데이터에 기록된 GTID 를 적용할지 여부 및 적용 방식 (기본값 off)
- skipBinlog : true 로 지정시 SET sql_log_bin=0 를 실행하여 복원시에 사용되는 명령어를
바이너리 로그에 저장하지 않는다. (기본값 false)
- loadIndexes : false 지정시 복원 대상 테이블의 보조 인덱스를 생성하지 않는다. (기본값 true)
- deferTableIndexes : 보조 인덱스 생성 시점
off : 테이블 로드중에 모든 인덱스 생성
fulltext : fulltext 인덱스만 테이블 로드후 인덱스 생성
all : 테이블 로드시에는 pk 만 생성하고 나머지 인덱스는 로드후 생성
- analyzeTables : 테이블 로드 후 ANALYZE TABLE 실행 여부 (기본값 off)
- characterSet : 복원시 사용할 캐릭터 셋
- schema : 덤프시 사용할 기본 스키마
- excludeSchemas : 복원시 제외할 스키마 지정
- includeSchemas : 지정된 스키마만 복원
- excludeTables : 복원시 제외할 테이블 지정
- includeTables : 지정된 테이블만 복원
- loadDdl : true 로 지정시 DDL 만 복원, 데이터는 복원 안함
- loadData : true 로 지정시 데이터만 복원, DDL 복원 안함
- loadUsers : 계정 복원 여부
- excludeUsers : 복원시 제외할 계정 지정
- includeUsers : 지정한 계정만 복원
- createInvisiblePKs : true 로 지정시 PK 가 없는 테이블 복원시 PK 추가
복원 테스트
이전에 백업한것으로 복원테스트 (역시 백업/복원 속도는 xtrabackup 이 최고다. util.loadDump 는 복원 속도가 아쉽다.)
local_infile 이 on 으로 지정안되서 에러 발생

set global general_log = on; 후 다시 시도
4 thds loading 지정한 thread 수만큼 덤프 파일을 로딩한다. (PC에 hyper-v로 테스트 하는거라 thread 4로 지정)
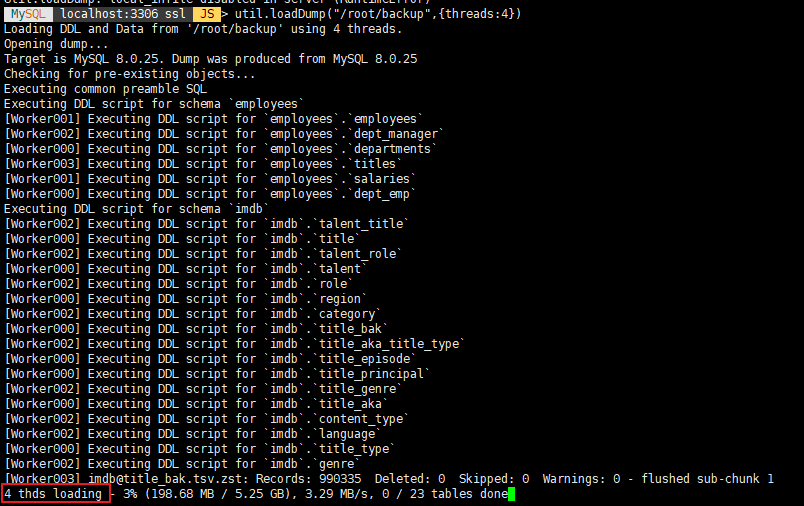
VM 인거 감안하고 3시간 39분.. ㅡ_ㅡ);;

general_log 와 진행 상태 파일을 열어보자
먼저 진행 상태 파일 DDL , DATA 로드 등의 정보가 기록되어 있다.

general_log 특별한게 없다.
참고
https://dev.mysql.com/doc/mysql-shell/8.0/en/mysql-shell-utilities-load-dump.html
'MySQL > Admin' 카테고리의 다른 글
| 대용량 테이블 컬럼 데이터 타입 변경 (0) | 2021.05.27 |
|---|---|
| mysql-shell util.dumpInstance (병렬 백업, PK 없는 테이블 백업) (0) | 2021.05.23 |
| mysql-shell util.dumpInstance (0) | 2021.05.18 |
| mysql shell (패스워드 저장 부분) (0) | 2021.05.16 |
| ibdata 파일 축소 (0) | 2021.05.11 |